Blog
Part 2: About the characteristics of CBT and the creation of high-quality Test questions (all 3 parts)
- Test Development Service
- CBT
item response theory
With CBT, Candidate are able to flexibly choose their test dates, so it is common to prepare multiple test versions to prevent questions from being leaked.
Raw scores are directly affected by the difficulty of the exam version, so when using multiple exam versions, candidates who happen to be assigned to the easier exam version may have an advantage. In order to eliminate this inequity, it would be best to adjust the difficulty level for each exam version and use test takers' scores instead of raw scores. In order to adjust the difficulty level for each exam version, you first need to know the difficulty of the exam version and the exam questions themselves. However, indicators such as average scores and passing rates (see: "Part 1: Characteristics of CBT and the creation of high-quality test questions") depend on the ability level of the examinee group, so these indicators can be evaluated more objectively. We need a framework that allows us to evaluate the degree of That is IRT. Using IRT, it is possible to determine the difficulty level of test questions, which is different from the pass rate and does not depend on the level of the group, from test accuracy data. We will explain the concept of IRT using an example of multiple-choice test questions that are graded on either correct or incorrect answers.In IRT, the probability of getting a correct answer to a test question is broken down into two factors: the difficulty of the test question and the test taker's ability level, and expressed in a mathematical formula.
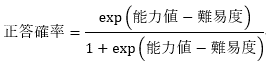
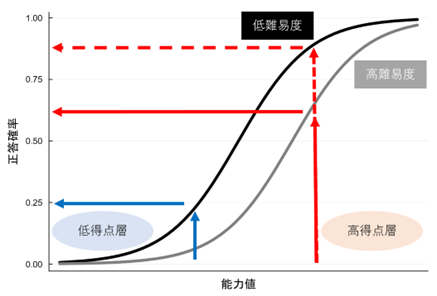
The difficulty level of each test question and Candidate 's ability score are calculated from the actual Test Result. If information on correct and incorrect answers for all test questions is obtained, the difficulty and ability values are set to the values that give the highest probability of obtaining the pattern of correct and incorrect answers. Within a single test answer data set, the lower the passing rate of test questions, the higher the difficulty level, and the higher Candidate 's correct answer rate, the higher the ability value. The one-parameter logistic model described here is the simplest IRT model. In addition, the discriminative power of the test questions ((Reference: ` `Part 1: Characteristics of CBT and the creation of high-quality test questions'') (expressed by the slope of the probability of correct answer in IRT) is taken into consideration. There are various derivative forms, such as the model, a model that takes into account the possibility of getting the correct answer even if you choose randomly in a multiple Prometric choice format, and a model that can be applied to tests with partial marks. We are proposing a model.
Equalization
By the way, there are countless combinations of IRT difficulty levels and ability scores that result in exactly the same correct answer rate. For example, in the one-parameter logistic equation, the probability of a correct answer for a test Candidate whose ability score is the same as the difficulty level of the exam question is 0.5 (50%), but the specific numerical values of the difficulty level and ability value in this case are Since it can be either 0 or 1, you cannot set it to one value without doing anything. Therefore, the center point of the difficulty of the test version is generally set so that the average difficulty of the test version is exactly 0. Based on the average difficulty level, if the combination of other questions included in the exam version changes, the difficulty value calculated for that exam version will change, even if the exam questions are the same. Equalization can be said to be the process of standardizing the meaning of the numerical difficulty level in test versions that consist of different combinations of test questions.
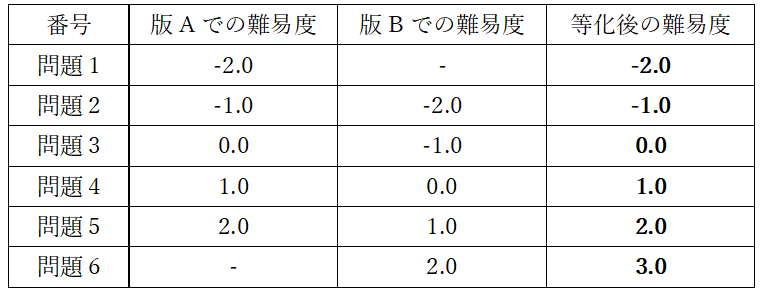
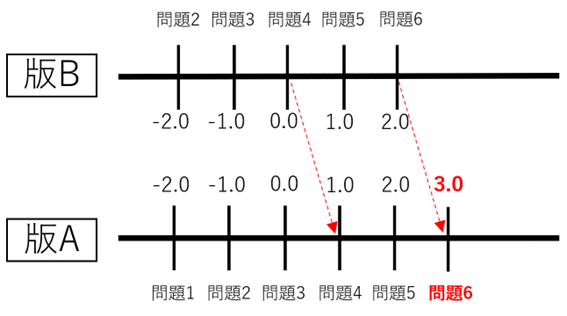
Finally, Candidate 's ability score is calculated based on the equalized difficulty level. Typically, Candidate 's score is calculated by appropriately converting the IRT proficiency score to fit a number between 0 and 100. This is called a scale score. Even if the test versions are different, if they are equalized, fair comparisons and pass/fail decisions can be made using this scale score. In reality, the numbers fluctuate minutely depending on Candidate 's answer data, so they will not be equalized as clearly as this. When equating actual exam questions, psychometricians calculate the equating coefficients by taking into account small numerical fluctuations in common items.



Questions about introducing CBT, consultation on operation, fees, etc.
If you have any questions, please feel free to contact us.